
Before I’ll start with the code some thoughts what has to bee done and what is additional work.
Data structure
How should the content be structured to display it to the user? The easiest way is to implement something that feels like a folder structure for navigation and add tags to get some clusters.
Entities
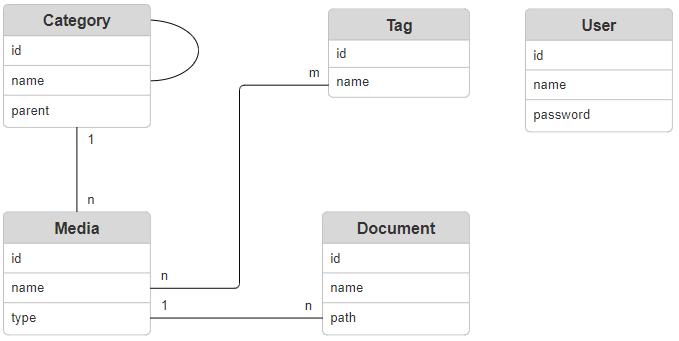
- The category entity should work like a folder-structure. It references one parent category entity and might have some sub/child-categories.
- The media entity links to category to get something similar like a path. Media groups contain multiple documents. In this way for example an audio book with more then one file can be accomplished.
- The document entity references a single file. The
pathmight contain a file path as well as a reference to a S3. - The tag entity clusters the media independent on category or media-type. For example it could group all media with excavator (song, instruction, images, …)
- The user entity represents a basic user. For now this will be real basic and will be moved in future to the authentication service.
REST
The Frontend should communicate via REST with the Backend
Converter
To get an abstraction between the DB-Entities and the Rest-Endpoint we’ll implement some converters.
DTOs & Views
DTOs will act as a abstraction of an Entity. Views are an specialized object which might contain only a reduced set of an entity or a mix of several entities.
Database
As productive and development database I’ll use PostgreSQL. The schema is created by JPA
spring:
jpa:
database-platform: org.hibernate.dialect.PostgreSQLDialect
show-sql: true
generate-ddl: true
hibernate:
ddl-auto: create-drop
properties:
hibernate.jdbc.time_zone: UTC
hibernate.format_sql: trueThe attribute ddl-auto: create-drop creates the schema and the tables for the entities. Liquibase or something similar would be a much better approach, but would take much more effort for now.
Bootstrap
To get some initial data I’ll do this direct via Java. Like the setup of the DB schema technical it would be a much better approach to do this with Liquibase. The benefit of using the CRUD-Services is that these services can be tested on the bootup.
@Component
@DependsOn({"userBootstrap"})
public class CategoryBootstrap {
@PostConstruct
public void init() {
...
}
}Document storage
As storage I’ll use Minio which is fully compatible with S3. I’m using tobi312/minio because it works on my raspberry pi. Feel free to use a different container like minio/minio.
This part of my docker-compose-file shows the configuration. of the minio-service
minio:
container_name: minio
image: tobi312/minio:latest
restart: always
command: [ "server", "--address", ":9000", "--console-address", ":9001", "/data" ]
environment:
MINIO_ROOT_USER: admin
MINIO_ROOT_PASSWORD: "TODO"
ports:
- "9000:9000"
- "9001:9001"
volumes:
- "/opt/minio/data:/data:rw"
healthcheck:
test: [ "CMD", "curl", "--fail", "http://localhost:9000/minio/health/live" ]
interval: 60s
timeout: 10s
retries: 3
networks:
- curatornet